GPT-5.5 vs Claude Opus 4.6 vs Gemini 3.1 Pro API Pricing 2026
GPT-5.5, Claude Opus 4.6, and Gemini 3.1 Pro all sit in the “serious work” tier of AI APIs. They can write code, debug production incidents, analyze long documents, and power agents that do more than answer one chat message.
They also price very differently. If you pick one model as your default for every request, you’ll either overspend or leave quality on the table. The right question is not “which model is best?” It is “which model should handle this kind of work, at this latency and cost?”
Short version: use GPT-5.5 for balanced product workloads and structured generation, Claude Opus 4.6 for hard coding and high-stakes reasoning, and Gemini 3.1 Pro when long context matters more than maximum first-pass precision.
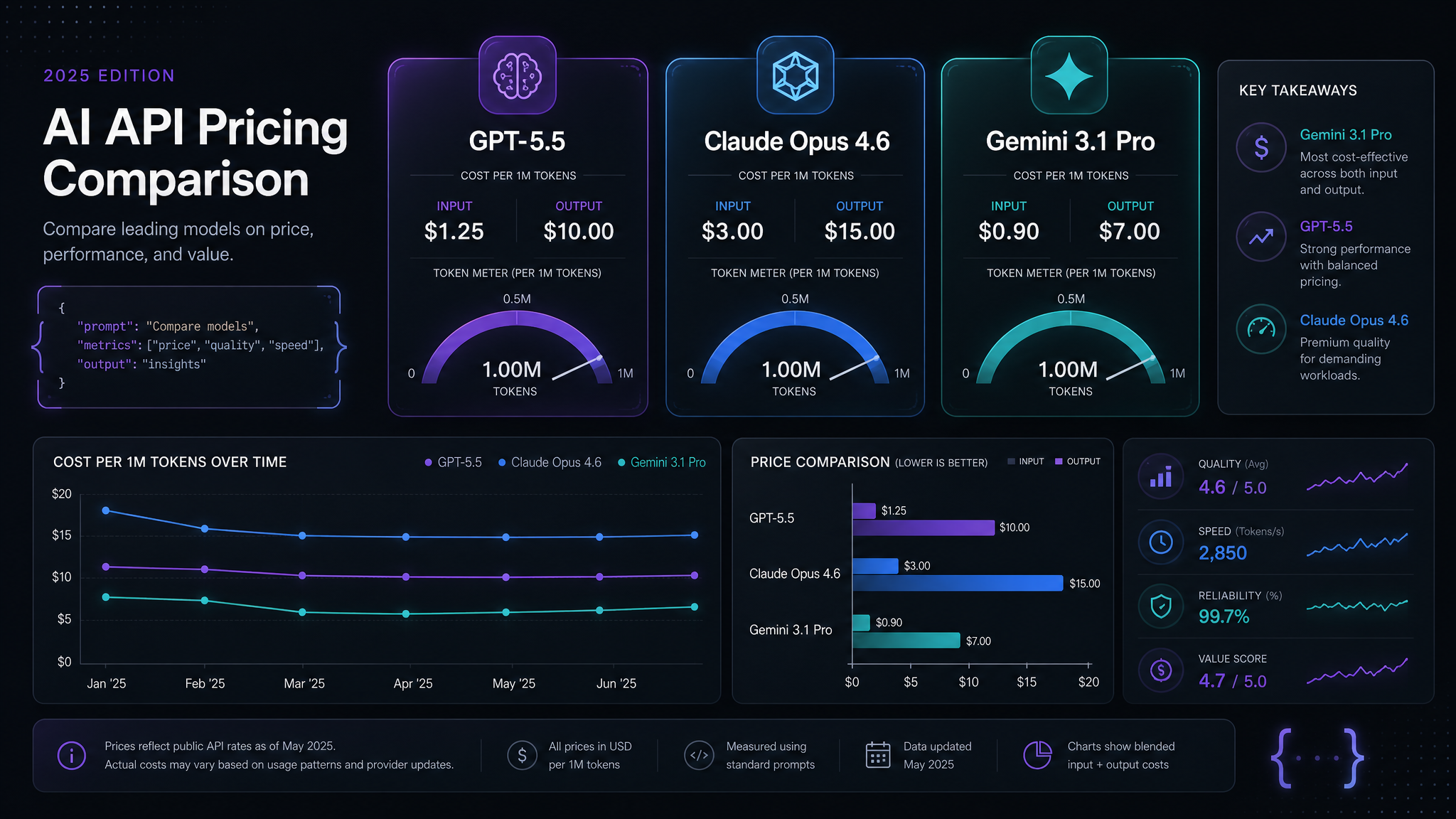
Pricing Snapshot
Public pricing moves fast, and gateways may package credits differently. Treat this table as a practical May 2026 planning baseline, then check your provider before committing a budget.
| Model | Input / 1M tokens | Output / 1M tokens | Best fit |
|---|---|---|---|
| GPT-5.5 | ~$5 | ~$30 | Apps, agents, structured output, general coding |
| Claude Opus 4.6 | ~$15 | ~$75 | Complex refactors, careful reasoning, writing quality |
| Gemini 3.1 Pro | ~$2 | ~$12 | Long context, research, large-document workflows |
That spread matters. Opus can cost 2.5x GPT-5.5 on output and more than 6x Gemini 3.1 Pro. On a tiny prototype, who cares. On a production coding agent or document pipeline, the difference becomes real money within days.
Real Workload Math
Let’s price a common developer workload: 20,000 requests per month, each with 8,000 input tokens and 1,200 output tokens. That is not huge. A coding assistant can hit it quickly once you include file context, tool results, and retries.
| Model | Monthly input | Monthly output | Estimated cost |
|---|---|---|---|
| GPT-5.5 | 160M tokens | 24M tokens | ~$1,520 |
| Claude Opus 4.6 | 160M tokens | 24M tokens | ~$4,200 |
| Gemini 3.1 Pro | 160M tokens | 24M tokens | ~$608 |
Now the tradeoff is obvious. If Opus saves enough engineering time or reduces bad patches, it can justify the price. But using it for every classification, summary, JSON extraction, and low-risk autocomplete is just lighting budget on fire.
When GPT-5.5 Is the Right Default
GPT-5.5 is the most sensible default for many product teams because it sits between the other two on price and capability. It is strong at structured output, tool calling, normal app logic, and “good enough on the first try” coding tasks.
I’d start with GPT-5.5 when you’re building:
- Customer-facing assistants that need predictable tone and JSON output.
- Agents with tools, retrieval, and moderate reasoning depth.
- Code generation for isolated files, tests, scripts, and refactors under clear constraints.
- Workflows where latency and reliability matter as much as peak benchmark score.
The trap is using GPT-5.5 for everything just because it feels safe. If the prompt is mostly reading 400 pages of logs or contracts, Gemini may be cheaper. If the task is a hairy multi-file architecture change, Opus may produce fewer bad turns.
When Claude Opus 4.6 Earns Its Price
Claude Opus 4.6 is expensive, but expensive is not the same as overpriced. It shines when the cost of a wrong answer is higher than the token bill. Think: migration plans, security-sensitive changes, complex pull requests, ambiguous product specs, and writing where taste matters.
Use Opus for the last mile, not every mile. A cheaper model can gather context, summarize logs, draft a first pass, or produce candidate patches. Then Opus can review the risky part, make the final architectural call, or handle the one request where you really want deeper judgment.
Good routing rule: if a failure causes a human to spend 30 minutes untangling the result, send it to Opus. If a failure just means “retry with a clearer prompt,” start cheaper.
When Gemini 3.1 Pro Wins
Gemini 3.1 Pro is the obvious pick for long-context work. If your request includes a large repo slice, a long transcript, a bundle of PDFs, or a big support-history export, the model’s context economics can beat a smarter but pricier model.
It is especially useful for:
- Large document analysis and extraction.
- Repo-wide Q&A before a smaller patching task.
- Research synthesis where recall across the whole context matters.
- Cheap first-pass triage before sending a smaller, sharper prompt to GPT-5.5 or Opus.
The mistake is asking Gemini to do every hard coding decision just because the token price looks nice. Cheap context is powerful. It is not a substitute for careful routing.
A Simple Router Pattern
You do not need a fancy orchestration framework to cut costs. Start with a small model-selection function. Route by task type, risk, and context size.
def choose_model(task_type: str, input_tokens: int, risk: str) -> str:
if risk == "high":
return "claude-opus-4-6"
if input_tokens > 120_000:
return "gemini-3-1-pro"
if task_type in {"json_extraction", "summary", "classification"}:
return "gpt-5.5-mini"
return "gpt-5.5"This looks almost too simple, but it beats the default “one flagship model for everything” setup. Add logging and you’ll quickly see which routes save money and which ones hurt quality.
Calling Models Through One Endpoint
An OpenAI-compatible gateway keeps the code boring. You can swap models per request while keeping the same SDK, auth pattern, retries, and observability. Here is a Node.js example:
import OpenAI from "openai";
const client = new OpenAI({
apiKey: process.env.KISSAPI_API_KEY,
baseURL: "https://api.kissapi.ai/v1"
});
const completion = await client.chat.completions.create({
model: "gpt-5.5",
messages: [
{ role: "system", content: "Return concise, valid JSON." },
{ role: "user", content: "Extract the invoice number and total from this text..." }
],
temperature: 0.2
});
console.log(completion.choices[0].message.content);To test another model, change the model name:
curl https://api.kissapi.ai/v1/chat/completions \
-H "Authorization: Bearer $KISSAPI_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"model": "claude-opus-4-6",
"messages": [{"role":"user","content":"Review this migration plan for hidden risks."}]
}'KissAPI is useful here because it lets you keep one API key and one OpenAI-compatible integration while testing multiple frontier models. The product decision becomes a routing decision, not a rewrite.
Cost Controls That Actually Help
- Log input and output tokens by route. Average cost per request is more useful than total bill shock.
- Cap context before routing. If a user pastes a giant file, summarize or chunk it first.
- Use cheaper models for preparation. Summaries, extraction, and deduping rarely need the top model.
- Escalate only on uncertainty. Ask a cheaper model to mark confidence, then send low-confidence cases to Opus.
- Cache stable prompts and retrieved context. Many agents resend the same instructions and docs every turn.
My Recommendation
If you are starting from zero, make GPT-5.5 your default, Gemini 3.1 Pro your long-context reader, and Claude Opus 4.6 your expert reviewer. That three-lane setup is cheaper than an Opus-only stack and safer than trying to make the cheapest model do everything.
For teams already running production traffic, do not switch everything at once. Mirror 5% of requests, compare quality, and track cost per successful task rather than cost per token. Tokens are not the product. Completed work is.
Compare models with one API key
Use KissAPI to route GPT, Claude, Gemini, and other models through one OpenAI-compatible endpoint. Start with free credits and test your own workload.
Start Free