Codex CLI API Fallback Routing Guide 2026: Keep Coding Agents Online
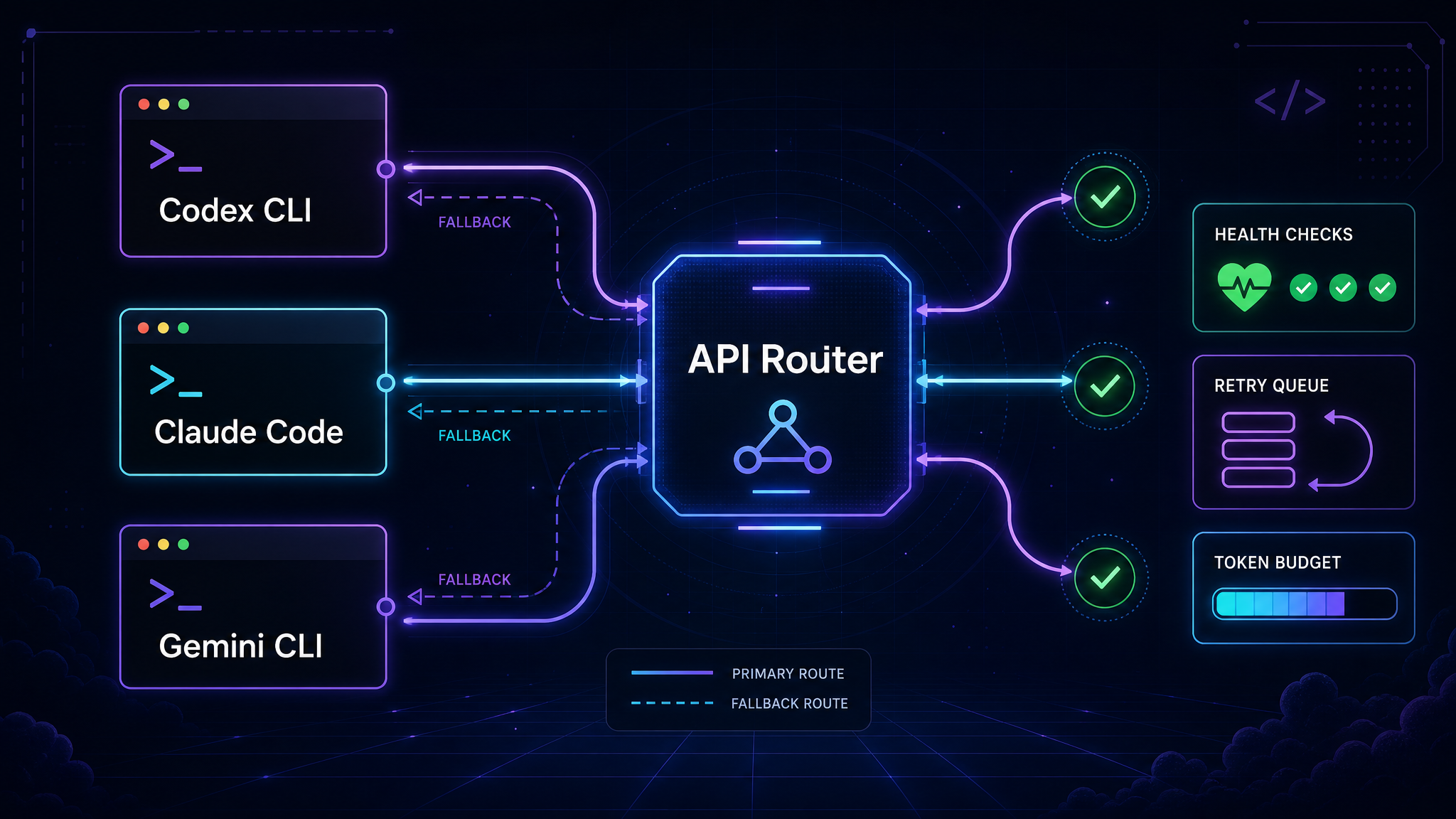
Codex CLI is useful until it hits the two problems every coding agent eventually hits: the model gets slow, or the API says no. That “no” might be a 429, a quota wall, a regional outage, a context limit, or a tool-call response that works in the web app but breaks through your local CLI.
The fix isn’t to keep a second terminal open and manually switch providers. The better pattern is API fallback routing: one OpenAI-compatible endpoint in your coding tool, with routing rules behind it. Codex CLI can stay pointed at one base URL while the router decides when to retry, when to downgrade, and when to send the task to a different model.
This guide shows a practical setup. It works for Codex CLI, and the same pattern applies to Claude Code, Gemini CLI, Cline, Aider, Cursor, OpenCode, or any tool that accepts a custom API base URL.
The goal: boring reliability
A coding agent fallback router should do five things:
- Keep one client config. Your CLI points to one API endpoint, not five different providers.
- Retry only safe failures. Retry 429, 500, 502, 503, 504, and network timeouts. Don’t retry bad prompts, auth errors, or context overflow forever.
- Fallback by task type. Cheap model for file search and summaries, strong code model for edits, reasoning model for architecture.
- Cap token spend. Stop long sessions from burning $20 because an agent loops on a failing test.
- Expose enough logs. You need to know which model actually handled the request.
Opinionated rule: don’t route by benchmark rank alone. Route by failure mode. A slightly weaker model that returns in 8 seconds is better than a “best” model that times out during a migration.
Recommended routing table
Start with a simple three-lane table. You can make it smarter later, but this is enough for most teams.
| Task | Primary | Fallback | Why |
|---|---|---|---|
| Small edits, lint fixes | Fast mini model | Claude Sonnet / GPT-5.5 | Latency matters more than depth |
| Multi-file coding | Claude Sonnet / GPT-5.5 | Gemini 3.1 Pro | Good code quality, enough context |
| Large repo analysis | Gemini 3.1 Pro | Claude Sonnet | Long context is the point |
| Architecture decisions | Reasoning model | Claude Opus / GPT-5.5 | Pay for thinking only when needed |
| Extraction, changelog, commit message | Cheap model | Fast mini model | No need for frontier tokens |
If you use KissAPI, you can keep this simple because Claude, GPT, Gemini, and other models sit behind one OpenAI-compatible endpoint. But the same design works if you run your own proxy in front of multiple providers.
Configure Codex CLI with one endpoint
The exact config location can vary by Codex CLI version, but the idea is always the same: set one API key, one base URL, and one default model alias. The alias can be real, like gpt-5.5, or virtual, like coding-agent-auto, if your gateway supports model aliases.
export OPENAI_API_KEY="your_api_key"
export OPENAI_BASE_URL="https://api.kissapi.ai/v1"
export OPENAI_MODEL="coding-agent-auto"Before you trust the CLI, test the endpoint with curl. It’s boring, but it saves you from debugging the wrong layer.
curl https://api.kissapi.ai/v1/chat/completions \
-H "Authorization: Bearer $OPENAI_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"model": "coding-agent-auto",
"messages": [
{"role": "user", "content": "Return only: router-ok"}
],
"max_tokens": 20
}'If this fails, Codex CLI will fail too. Fix authentication and model naming first. Don’t start changing agent prompts yet.
Retry rules that won’t create a storm
The most common mistake is retrying everything. That turns a small outage into a retry storm. Use this split instead:
| Status / Error | Action | Notes |
|---|---|---|
| 401 / 403 | Do not retry | Bad key, permission, or account issue |
| 400 context length | Compress context | Fallback won’t help unless the fallback has more context |
| 429 | Backoff, then fallback | Honor Retry-After if present |
| 500 / 502 / 503 / 504 | Retry once, then fallback | Usually transient provider trouble |
| Timeout | Retry with shorter timeout or fallback | Never let agents hang forever |
Here’s a compact Python router. It tries the primary model, retries once on transient errors, then falls back. In production, you’d add logging, per-model health state, and request IDs.
import os, time, requests
API_KEY = os.environ["OPENAI_API_KEY"]
BASE_URL = os.getenv("OPENAI_BASE_URL", "https://api.kissapi.ai/v1")
TRANSIENT = {429, 500, 502, 503, 504}
ROUTES = {
"small-edit": ["gpt-5.5-mini", "claude-sonnet-4-6"],
"code": ["claude-sonnet-4-6", "gpt-5.5", "gemini-3-1-pro"],
"long-context": ["gemini-3-1-pro", "claude-sonnet-4-6"],
}
def chat(task, messages, max_tokens=1200):
models = ROUTES.get(task, ROUTES["code"])
last_error = None
for model in models:
for attempt in range(2):
r = requests.post(
f"{BASE_URL}/chat/completions",
headers={
"Authorization": f"Bearer {API_KEY}",
"Content-Type": "application/json",
"X-Route-Task": task,
},
json={"model": model, "messages": messages, "max_tokens": max_tokens},
timeout=45,
)
if r.status_code == 200:
return {"model": model, "data": r.json()}
if r.status_code not in TRANSIENT:
raise RuntimeError(f"Non-retryable error {r.status_code}: {r.text[:300]}")
last_error = f"{r.status_code}: {r.text[:200]}"
retry_after = int(r.headers.get("Retry-After", "0") or 0)
time.sleep(retry_after or (1.5 * (attempt + 1)))
# model failed twice; try the next model
raise RuntimeError(f"All fallback models failed. Last error: {last_error}")Node.js version for tool wrappers
If you’re wrapping Codex CLI inside a local dev script, Node.js is often more convenient. This example uses the official OpenAI SDK shape and switches models after transient failures.
import OpenAI from "openai";
const client = new OpenAI({
apiKey: process.env.OPENAI_API_KEY,
baseURL: process.env.OPENAI_BASE_URL || "https://api.kissapi.ai/v1",
});
const transient = new Set([429, 500, 502, 503, 504]);
const routes = {
code: ["claude-sonnet-4-6", "gpt-5.5", "gemini-3-1-pro"],
cheap: ["gpt-5.5-mini", "claude-haiku-4-5"],
};
export async function routedChat(task, messages) {
for (const model of routes[task] || routes.code) {
try {
const res = await client.chat.completions.create({
model,
messages,
max_tokens: 1200,
});
return { model, text: res.choices[0].message.content };
} catch (err) {
const status = err.status || err.response?.status;
if (!transient.has(status)) throw err;
await new Promise(r => setTimeout(r, 1200));
}
}
throw new Error("All routed models failed");
}Add a token budget before you add more models
More fallback options can hide waste. If an agent keeps failing tests because the instructions are wrong, fallback will just make the failure more expensive. Put a hard budget around each session.
SESSION_TOKEN_LIMIT=250000
REQUEST_TOKEN_LIMIT=50000
MAX_AGENT_TURNS=18
MAX_RETRIES_PER_REQUEST=1For coding agents, I like these defaults:
- Exploration: cheap model, 30K request cap, no edits allowed.
- Implementation: strong code model, 50K request cap, one retry.
- Debugging: same model for two turns max, then require a new plan.
- Review: different model than implementation if possible.
That last point is underrated. If Claude wrote the patch, let GPT or Gemini review it. If Codex made the migration, let Claude review the diff. Same-model review catches fewer blind spots.
What to log
Good routing logs don’t need to expose prompt content. Log the operational facts:
- Request ID
- Task type
- Primary model
- Final model used
- Status code
- Input and output token counts
- Latency
- Fallback reason
With those fields, you can answer the questions that matter: “Which model is causing slowdowns?”, “Are we falling back too often?”, “Did yesterday’s cost spike come from retries or bigger prompts?”
Run Codex CLI Through One Reliable API Endpoint
KissAPI gives you OpenAI-compatible access to Claude, GPT, Gemini, and more, so your coding agents can route around outages, rate limits, and cost spikes without rewriting your tools.
Start Free →Common setup mistakes
Using fallback for auth errors
If the key is invalid, every model will fail. Stop immediately on 401 or 403. A fallback chain can’t fix a broken credential.
Letting long-context requests fallback to short-context models
If a 500K-token repo summary fails on a long-context model, don’t blindly send it to a 200K model. First compress the context or split the repo into chunks.
Not separating user-facing latency from background work
Codex CLI commands feel broken when they sit silent for two minutes. For interactive work, prefer fast failure plus fallback. For background refactors, a slower but more accurate model can be fine.
Bottom line
Codex CLI fallback routing is not fancy infrastructure. It’s a small reliability layer with a big payoff. Point the CLI at one endpoint, retry the failures that deserve retries, fallback by task type, and cap the session before an agent loop eats your budget.
The teams that get the best value from coding agents in 2026 won’t be the teams using one “best” model for everything. They’ll be the teams with routing discipline.